Zendesk Enterprise: global satisfaction score
- could be very old (up to 20 years!)
- could not be accurate anymore
- could not represent the views of the author anymore
- could be in le French
One of my biggest grief about the Enterprise plan of Zendesk is its lack of support for the satisfaction score. I mean, all accounts have their own satisfaction score like on a regular plan but we lack a way to have the global score of all branded spokes added to the one of the main hub.
I needed this. So I fixored this 🙂 . Plus, the following Python script will calculate your satisfaction score even if you have less than 100 satisfaction feedback on your account. And finally, I push the score to Ducksboard, a very cool real time dashboard in which you can see all your business metrics.
So basically, a simple Python scripts reads the account.zendesk.com/satisfaction.json file, counts the number of 0 (bad) and 1 (good) feedbacks. It does this for each of your accounts so you can add more than the 3 I have below. Then some simple maths are applied to make a sum of all good and back feedbacks and give you a result in percent.
You need to trigger this script via a cron tab, for example, so that every x hour the latest data from your Zendesk accounts will be read. And at that moment it will also shoot the results to the Ducksboard API (I just left the code there, simply delete this if you don’t need it).
My second grief about the Enterprise plan is that it lacks the support of placeholders throughout the spokes (for automated emails, like hello {{ticket_requester_name}} ), but that’s for another post 😉
The script
#!/usr/bin/env python
"""Fetches the satisfaction score of Zendesk spokes and gathers it in one spot. You will need to call this script with a CRON so that it is launched every day, for example. As a bonus, I left the code about Ducksboard. It's a cool system to display BI and monitoring stuff regarding your service. Simply replace the API_KEY and END_POINT values."""
__author__ = "Arnaud de Theux" __web__ = "http://arnaud.detheux.org" __twitter__ = "@AdeTheux"
from urllib import urlopen import urllib import sys import os
###Below the 3 spokes we have at the moment, simply put your Zendesk account name
#spoke 1
good = 0
bad = 0
data = urlopen("http://SPOKE1.zendesk.com/satisfaction.json").readlines()[0]
good = data.count('1')
bad = data.count('0')
#spoke 2
good1 = 0
bad1 = 0
data = urlopen("http://SPOKE2.zendesk.com/satisfaction.json").readlines()[0]
good1 = data.count('1')
bad1 = data.count('0')
#spoke 3
good2 = 0
bad2 = 0
data = urlopen("http://SPOKE3.zendesk.com/satisfaction.json").readlines()[0]
good2 = data.count('1')
bad2 = data.count('0')
###Makes a simple addition sum_good = good + good1 + good2 sum_bad = bad + bad1 + bad2
###You can now simply call sum_good and sum_bad to display it all over the interwebs.
###This is the code to push the values in bubbles in your Ducksboard account
command = "curl -u API_KEY:ignored -d '{"value": %d}' https://push.ducksboard.com/values/END_POINT/" % sum_good
command2 = "curl -u API_KEY:ignored -d '{"value": %d}' https://push.ducksboard.com/values/END_POINT/" % sum_bad
print command os.system(command) print command2 os.system(command2)
Demo Well in this case there is not much to show :) Either you just run the script and return the results wherever you want, or you push them to Ducksboard and it can look like this:
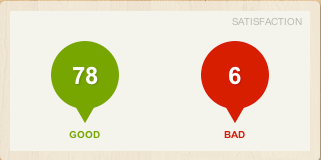
Code The source code is available here.